Классы сущностей Java могут иметь иерархическую структуру и существует ряд стратегий отображения этой структуры в БД. В частности используются подходы «отдельная таблица на каждый конкретный класс» и «одна таблица для всех наследников». У каждого из подходов есть свои преимущества и недостатки. Hibernate позволяет использовать эти две стратегии одновременно.
Например, если у нас есть класс Person и у него три наследника: Client, Employee и Freelancer, мы можем хранить данные двух наследников (Client и Employee) в одной таблице, а данные Freelancer в отдельной таблице, у которой будет внешний ключ на id общей таблицы.
Подготовка
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Также добавим в application.properties настройку, позволяющую видеть создаваемый Hibernate’ом SQL в консоли:
spring.jpa.show-sql=true
Код
Создадим абстрактный класс-предок, от которого будут наследоваться конкретные классы:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @DiscriminatorColumn(name = "PERSON_TYPE") public abstract class Person { @Id @GeneratedValue protected Long id; protected String name; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Мы помечаем класс Person аннотацией @Entity. Кроме того мы добавляем аннотацию @Inheritance с параметром strategy = InheritanceType.SINGLE_TABLE, так как хотим, чтобы наследники этого класса сохраняли данные в одну таблицу. И используем аннотацию @DiscriminatorColumn, в которой с помощью параметра name задаём имя колонки-дискриминатора для определения того, к какому наследнику относиться та или иная строка.
Настройка класса-предка полностью аналогична настройкам при использовании подхода «одна таблица для всех наследников». И точно так же в соответствии с требованиями такого подхода будут настроены два класса-потомка (каждй в своём файле):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
@Entity @DiscriminatorValue("CLIENT") public class Client extends Person { private String phone; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } @Entity @DiscriminatorValue("EMPLOYEE") public class Employee extends Person { private String personnelNumber; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Таким образом данные, отображаемые из объектов классов Client и Employee будут храниться в одной таблице PERSON со всеми преимуществами и недостатками этого подхода.
Создадим третий класс-наследник Person, данные которого мы хотели бы хранить в отдельной таблице. У него будут уже другие настройки:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@Entity @DiscriminatorValue("FREELANCER") @SecondaryTable( name = "FREELANCER", pkJoinColumns = @PrimaryKeyJoinColumn(name = "FREELANCER_ID") ) public class Freelancer extends Person { @Column(table = "FREELANCER", nullable = false) private String duties; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Мы помечаем этот класс аннотациями @Entity и @DiscrimintorValue, так что в этом отношении этот класс похож на других наследников.
Кроме того, мы помечаем этот класс аннотацией @SecondaryTable, указывая Hibetnate’у, что хотим хранить данные полей этого класса в отдельной таблице, в отличие от других наследников Person.
- Параметр name задаёт имя таблицы для данных этого класса.
- Параметр pkJoinColumns задаёт массив колонок, которые будут содержать внешние ключи на главную таблицу. В нашем случае это всего одна колонка и задаём мы её с помощью аннотации @PrimaryKeyJoinColumn, где параметр name = «FREELANCER_ID» указывает имя этой колонки. Если бы нужно было задать несколько колонок с внешними ключами, то это выглядело бы так:
|
1 |
pkJoinColumns = {@PrimaryKeyJoinColumn(name = "FIRST_ID"), @PrimaryKeyJoinColumn(name = "SECOND_ID")} |
Поля этого класса мы помечаем аннотацией @Column, в которой с помощью параметра table указываем, что хотим хранить данные этого поля в отдельной таблице FREELANCER. Кроме того, здесь мы можем наложить на поле ограничение NOT NULL, что было бы невозможно, если бы данные этого поля хранились в общей, а не отдельной таблице.
Напишем репозиторий для родительского класса Person:
|
1 2 3 4 |
@Repository public interface PersonRepository<T extends Person> extends JpaRepository<T, Long> { List<T> findByName(String name); } |
Напишем репозитории для классов-наследников (каждый в своём файле):
|
1 2 3 4 5 6 7 8 9 10 11 |
@Repository public interface ClientRepository extends PersonRepository<Client> { } @Repository public interface EmployeeRepository extends PersonRepository<Employee> { } @Repository public interface FreelancerRepository extends PersonRepository<Freelancer> { } |
Репозитории классов-наследников не обязаны наследовать PersonRepository, а могут наследовать JpaRepository<T, ID>. Но в данном случае это удобно, чтобы у них у всех унаследовался метод findByName().
Напишем тест, который продемонстрирует вышеизложенное:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
@SpringBootTest @TestMethodOrder(MethodOrderer.OrderAnnotation.class) class SpringHibernatePostgresqlApplicationTests { @Autowired ClientRepository clientRepository; @Autowired FreelancerRepository freelancerRepository; @Autowired PersonRepository<?> personRepository; @Test @Order(1) void clientTest() { Client client = new Client("Irina", "+7 123 456 78 90"); clientRepository.save(client); Client clientInDb = clientRepository.findById(client.getId()).get(); assertEquals(client, clientInDb); } @Test @Order(2) void freelancerTest() { Freelancer freelancer = new Freelancer("Vladimir", "Настраивать компьютеры"); freelancerRepository.save(freelancer); Freelancer freelancerInDb = freelancerRepository.findById(freelancer.getId()).get(); assertEquals(freelancer, freelancerInDb); } @Test @Order(3) void personTest() { List<? extends Person> persons = personRepository.findByName("Irina"); assertFalse(persons.isEmpty()); assertTrue(persons.get(0) instanceof Client); } } |
В первых двух тестовых методах мы создаём объекты классов Client и Freelancer соответственно, сохраняем их в БД, затем достаём по id и убеждаемся, что извлечённые данные соответствуют тому, что мы сохраняли.
В методе personTest() мы проверяем, что у нас есть возможность делать полиморфную выборку всех объектов классов-наследников person, как бы они ни хранились в БД.
Посмотрим на схему БД, созданную Hibernate’ом:
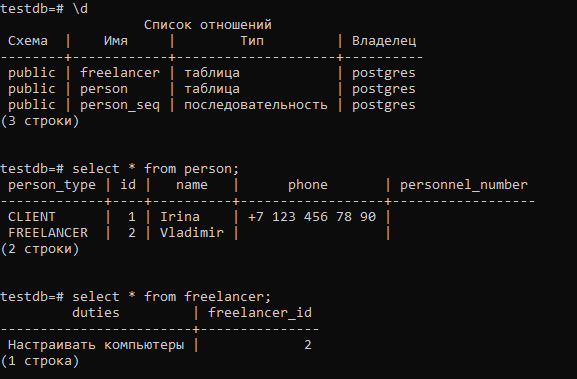
Для данных классов Client и Employee создана общая таблица PERSON, тогда как для данных класса Freelancer используется отдельная таблица FREELANCER.
Тем не менее по структуре и содержимому таблицы PERSON мы видим, что в ней хранятся записи всех трёх наследников. Только для Client и Employee PERSON хранит вообще все данные, а для Freelancer хранит только данные общего поля name, а также id записи и значение колонки-дискриминатора PERSON_TYPE, которая заводится для того, чтобы можно было отличить, какая строка к какому классу-наследнику относится.
В таблице FREELANCER мы видим только данные поля duties, на которое мы повесили аннотацию, указывающую, чтобы его данные сохранялись именно в эту таблицу.
Рассмотрим подробней таблицу FREELANCER:
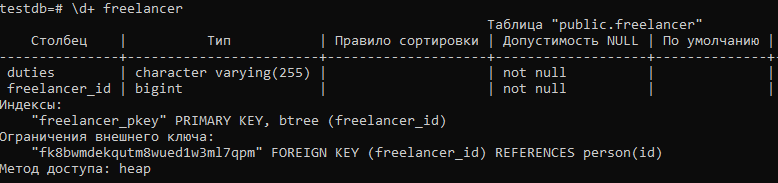
Мы видим, что благодаря аннотации
|
1 2 3 4 |
@SecondaryTable( name = "FREELANCER", pkJoinColumns = @PrimaryKeyJoinColumn(name = "FREELANCER_ID") ) |
была создана колонка FREELANCER_ID, которая с одной стороны является первичный ключом этой таблицы, с другой — ссылкой на PERSON.ID, являющегося общим идентификатором для всех наследников Person.
Также использование отдельной таблицы для данных класса Freelancer позволило нам наложить на колонку duties ограничение NOT NULL. Колонки PHONE и PERSONNEL_NUMBER общей таблицы PERSON не могут иметь такого ограничения и обеспечивать надлежащую заполненность таких колонок — задача java-кода.
Рассмотрим запросы, которые составляет Hibernate, когда делает выборку тех или иных данных.
Если мы делаем выборку через репозиторий наследника, пользующегося общей таблицей, в нашем случае — ClientRepository:
select c1_0.id,c1_0.name,c1_0.phone
from person c1_0
where c1_0.person_type='CLIENT' and c1_0.id=?
Hibernate просто ищет по общей таблице, фильтруя поиск по значению дискриминатора.
Если мы делаем выборку через репозиторий наследника, пользующегося отдельной таблицей, в нашем случае — FreelancerRepository:
select f1_0.id,f1_0.name,f1_1.duties
from person f1_0 left join freelancer f1_1 on f1_0.id=f1_1.freelancer_id
where f1_0.person_type='FREELANCER' and f1_0.id=?
Hibernate использует LEFT JOIN для соединения главной таблицы с отдельной, а также фильтр по дискриминатору.
Поиск через репозиторий предка — PersonRepository — выглядит следующим образом:
select p1_0.id,p1_0.person_type,p1_0.name,p1_0.phone,p1_0.personnel_number,p1_1.duties from person p1_0 left join freelancer p1_1 on p1_0.id=p1_1.freelancer_id
where p1_0.name=?
Hibernate через LEFT JOIN соединяет главную таблицу с отдельной и делает выборку по результирующей таблице.