Классы сущностей Java могут иметь иерархическую структуру и существует ряд стратегий отображения этой структуры в БД. Одной из стратегий является отображение всех наследников в одну таблицу по имени предка.
То есть, если классы Client и Employee наследуют класс Person, то Hibernate создаёт одну таблицу PERSON, в которой хранит данные, отображённые как из объектов класса Client, так и из Employee.
Такая таблица получается не нормализованной и вынуждена допускать то или иной количество nullable полей, что имеет свои недостатки и может быть неприемлемым. Однако у этого похода есть свои преимущества. В одной таблице хранятся данные о различных объектах предметной области, что позволяет делать выборку разных объектов по общим полям. Это, вероятно, самый быстрый способ создавать полиморфные списки объектов типа List<Person>, делая выборку из БД.
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Создадим абстрактный класс-предок для сущностей, отображаемых в БД:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @DiscriminatorColumn(name = "PERSON_TYPE") public abstract class Person { @Id @GeneratedValue protected Long id; protected String name; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
При таком подходе мы должны пометить родительский класс аннотацией @Entity. id-поле для всех наследников должно быть размещено именно здесь в предке. В конкретных классах-потомках создавать id-поле не нужно.
Hibernate создаст одну таблицу под названием PERSON (и сиквенс к ней), так как это предписывается аннотацией @Inheritance с параметром strategy = InheritanceType.SINGLE_TABLE. Все поля всех потомков будут иметь соответствующие колонки в этой таблице и колонки полей потомков будут допускать нуллы (nullable).
Поля предков могут не допускать значения null. Для этого поле (например, в этом примере поле name) должно быть помечено аннотацией @Column(nullable = false), тогда Hibernate при создании схемы БД наложит на соответствующую колонку ограничение NOT NULL.
Кроме того, мы помечаем класс-предок аннотацией @DiscriminatorColumn с параметром name = «PERSON_TYPE». Для каждой строки таблицы PERSON должно быть известно, в объекты какого класса-наследника нужно отображать её данные. Для этого создаётся специальная кологка-дискриминатор, в которую указывается дискриминатор класса (будет задан в потомках), к которому относится эта строка. Название такой колонки задаётся параметром name (мы назвали её PERSON_TYPE). Если аннотацию @DiscriminatorColumn не использовать или не задать параметр, то колонка всё равно будет создана и будет называться DTYPE.
Создадим конкретные классы-потомки, для каждого из которых будет создана своя таблица. Каждый класс в своём файле:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
@Entity @DiscriminatorValue("CLIENT") public class Client extends Person { private String phone; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } @Entity @DiscriminatorValue("EMPLOYEE") public class Employee extends Person { private String personnelNumber; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Мы также помечаем классы-потомки аннотацией @Entity, но собственных таблиц они иметь не будут. Кроме того, мы не создаём для них поле-идентификатор (id), они будут полагаться на аннотацию @Id в предке.
Аннотация @DiscriminatorValue позволяет задать имя дискриминатора для конкретного потомка. Затем в общей таблице будет создана специальная колонка, в которую для каждой строки будет делаться запись, к какому из классов потомков эта строка относится. Собственно различаться классы будут по заданному в @DiscriminatorValue значению.
Создадим репозиторий для класса предка:
|
1 2 3 4 |
@Repository public interface PersonRepository<T extends Person> extends JpaRepository<T, Long> { List<T> findByName(String name); } |
Создадим репозитории для классов-потомков (каждый в своём файле):
|
1 2 3 4 5 6 7 |
@Repository public interface ClientRepository extends PersonRepository<Client> { } @Repository public interface EmployeeRepository extends PersonRepository<Employee> { } |
Наследование репозиториями потомков репозитория PersonRepository не является обязательным. Они могут также наследовать JpaRepository<T, ID>. Но обычно мы этого хотим, чтобы репозитории потомков сразу имели методы поиска по полям предка. В нашем случае мы наследуем метод findByName(), что логично.
В коде можно будет использовать любой из репозиториев, в зависимости от конкретной потребности. Если нужна выборка по всем строкам общей таблицы, то используем репозиторий предка. Если нужна выборка по, например, только классу Client, то используем ClientRepository. Hibernate в таком случае использует в запросе дискриминатор в секции WHERE:
…where c1_0.person_type='CLIENT' and…
Напишем тест, который продемонстрирует вышеизложенное:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
@SpringBootTest @TestMethodOrder(MethodOrderer.OrderAnnotation.class) class SpringHibernatePostgresqlApplicationTests { @Autowired ClientRepository clientRepository; @Autowired EmployeeRepository employeeRepository; @Autowired PersonRepository<?> personRepository; @Test @Order(1) void clientTest() { Client client = new Client("Irina", "+7 123 456 78 90"); clientRepository.save(client); Client clientInDb = clientRepository.findById(client.getId()).get(); assertEquals(client, clientInDb); } @Test @Order(2) void employeeTest() { Employee employee = new Employee("Vladimir", "112233"); employeeRepository.save(employee); Employee employeeInDb = employeeRepository.findById(employee.getId()).get(); assertEquals(employee, employeeInDb); } @Test @Order(3) void personTest() { List<? extends Person> persons = personRepository.findByName("Irina"); assertFalse(persons.isEmpty()); assertTrue(persons.get(0) instanceof Client); } } |
Метод clientTest() создаёт объект соответствующего класса с некоторыми данными. С помощью репозитория сохраняет данные в единую таблицу. Затем убеждается, что если извлечь данные из базы по id, то они совпадают с сохранёнными. Если тест падает, убедитесь, что должным образом определены методы equals() и hashCode() и у класса Client, и у предка, класса Person.
Поверки, выполняемые тестовым методом employeeTest(), полностью аналогичны таковым у clientTest().
Метод personTest() показывает, что мы можем использовать PersonRepository для поиска по всей таблице.
Посмотрим, какую схему БД создал Hibernate на основании наших аннотаций. И что хранится в таблице после выполнения теста:
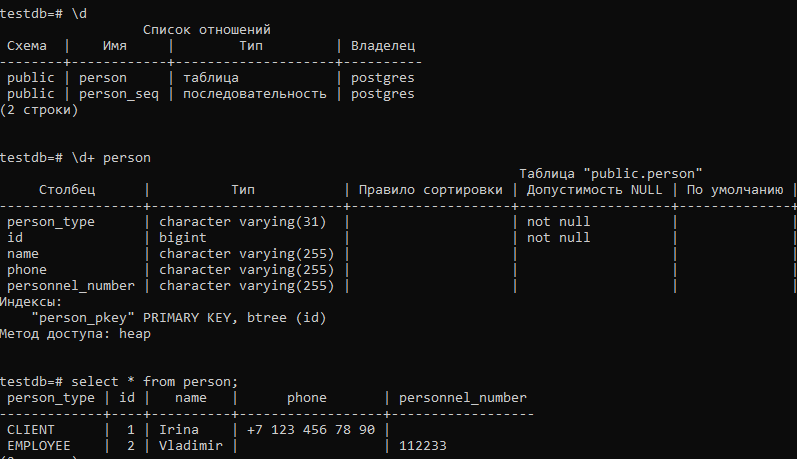
Мы видим, что создана одна общая таблица (как и ожидалось) для всех классов-потомков. У этой таблицы есть колонка-дискриминатор person_type. При сохранении строки в таблицу поле PERSON_TYPE заполняется соответствующим значением дискриминатора, после чего Hibernate легко отличает какая строка к какому классу потомку относится.
Схема данных при этом у нас не нормализована и ни при каких обстоятельствах мы не можем наложить NOT NULL ограничения на колонки, соответствующие полям классов-потомков (в нашем случае — phone и personnel_number). Иначе схема получится неработоспособной.