Классы сущностей Java могут иметь иерархическую структуру и существует ряд стратегий отображения этой структуры в БД. Одной из стратегий является отображение каждого конкретного класса в отдельную таблицу таким образом, что при запросе данных через репозиторий предка мы получим выборку по всем таким таблицам.
То есть, если классы Client и Employee наследуют класс Person, то Hibernate создаёт для каждого отдельную таблицу, при этом нам становится доступно использование единого репозитория PersonRepository, который будет в одном запросе делать выборку из обеих таблиц (через union) и, как следствие, легко формировать списки типа List<Person>.
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Также добавим в application.properties настройку, позволяющую видеть создаваемый Hibernate’ом SQL в консоли:
spring.jpa.show-sql=true
Создадим абстрактный класс-предок для сущностей, отображаемых в БД:
|
1 2 3 4 5 6 7 8 9 10 11 |
@Entity @Inheritance(strategy = InheritanceType.TABLE_PER_CLASS) public abstract class Person { @Id @GeneratedValue protected Long id; protected String name; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Отметим, что если мы хотим иметь доступ к полиморфизму, мы обязаны пометить такой родительский класс аннотацией @Entity, хотя для него и не будет создаваться отдельная таблица. Кроме того, id-поле для всех наследников также должно быть размещено именно здесь в предке. В конкретных классах-потомках создавать id-поле не нужно.
Hibernate будет создавать отдельную таблицу для каждого класса потомка и не будет создавать таблицу для этого родительского класса Person благодаря аннотации @Inheritance с параметром strategy = InheritanceType.TABLE_PER_CLASS.
Создадим конкретные классы-потомки, для каждого из которых будет создана своя таблица. Каждый класс в своём файле:
|
1 2 3 4 5 6 7 |
@Entity public class Client extends Person { private String phone; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
|
1 2 3 4 5 6 7 |
@Entity public class Employee extends Person { private String personnelNumber; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Эти конкретные классы-потомки также помечаются аннотацией @Entity, но у них, как мы сказали выше, нет id-поля, они его наследуют от предка.
Создадим репозиторий для класса предка:
|
1 2 3 4 |
@Repository public interface PersonRepository<T extends Person> extends JpaRepository<T, Long> { List<T> findByName(String name); } |
Этим репозиторием мы сможем воспользоваться для поиска одновременно по таблице CLIENT и EMPLOYEE (через union), которые будут созданы для соответствующих классов-наследников.
Создадим репозитории для Client и Employee (каждый в своём файле):
|
1 2 3 |
@Repository public interface ClientRepository extends PersonRepository<Client> { } |
|
1 2 3 |
@Repository public interface EmployeeRepository extends PersonRepository<Employee> { } |
Оба репозитория наследуют PersonRepository, что позволяет им использовать методы родителя, в данном случае метод findByName(), что логично, так как поле name расположено как раз в родителе и вероятно всем наследникам такой метод не помешает.
Если репозитории конкретных классов не будут наследовать репозиторий предка, а будут просто наследовать JpaRepository<T, ID>, то ничего принципиально не поменяется. Мы по-прежнему сможем использовать PersonRepository для поиска по двум таблицам сразу, а репозитории потомков для работы с таблицами по отдельности. Тем не менее, обычно такое наследование репозиториев делают для поиска по общим полям.
Напишем тест, который продемонстрирует работу Hibernate при таких настройках классов предметной области и их иерархии:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
@SpringBootTest @TestMethodOrder(MethodOrderer.OrderAnnotation.class) class SpringHibernatePostgresqlApplicationTests { @Autowired ClientRepository clientRepository; @Autowired EmployeeRepository employeeRepository; @Autowired PersonRepository<?> personRepository; @Test @Order(1) void clientTest() { Client client = new Client("Irina", "+7 123 456 78 90"); clientRepository.save(client); Client clientInDb = clientRepository.findById(client.getId()).get(); assertEquals(client, clientInDb); } @Test @Order(2) void employeeTest() { Employee employee = new Employee("Vladimir", "112233"); employeeRepository.save(employee); Employee employeeInDb = employeeRepository.findById(employee.getId()).get(); assertEquals(employee, employeeInDb); } @Test @Order(3) void personTest() { List<? extends Person> persons = personRepository.findByName("Irina"); assertFalse(persons.isEmpty()); assertTrue(persons.get(0) instanceof Client); } } |
Метод clientTest() создаёт объект соответствующего класса с некоторыми данными. С помощью репозитория сохраняет данные в базу, а затем убеждается, что если извлечь данные из базы по id, то они совпадают с сохранёнными. Если тест падает, убедитесь, что должным образом определены методы equals() и hashCode() и у класса Client, и у предка, класса Person.
Поверки, выполняемые тестовым методом employeeTest(), полностью аналогичны таковым у clientTest().
Метод personTest() показывает, что мы можем использовать PersonRepository для поиска по двум таблицам сразу. Созданная в предыдущих тестовых методах запись в таблицу CLIENT с полем NAME равным «Irina», будет найдена через PersonRepositoty. В консоли мы сможем увидеть такой SQL:
select p1_0.id,p1_0.clazz_,p1_0.name,p1_0.phone,p1_0.personnel_number from ( select id, name, phone, null::text as personnel_number, 1 as clazz_ from client union all select id, name, null::text as phone, personnel_number, 2 as clazz_ from employee ) p1_0 where p1_0.name=?
Все издержки, связанные с использование union в запросе, должны быть учтены заранее. Соответственно, если издержки неприемлемы, то запросы через родительский репозиторий делать не стоит.
Посмотрим на созданную схему БД:
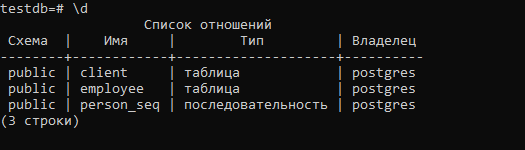
Для дочерних конкретных классов созданы отдельные таблицы. Для родительского класса отдельной таблицы нет. Но сиквенс создан по имени родительской таблицы и используется для обеих таблиц. Как следствие, номера id у двух таблиц не будут никогда пересекаться.
Сами таблицы выглядят следующим образом:
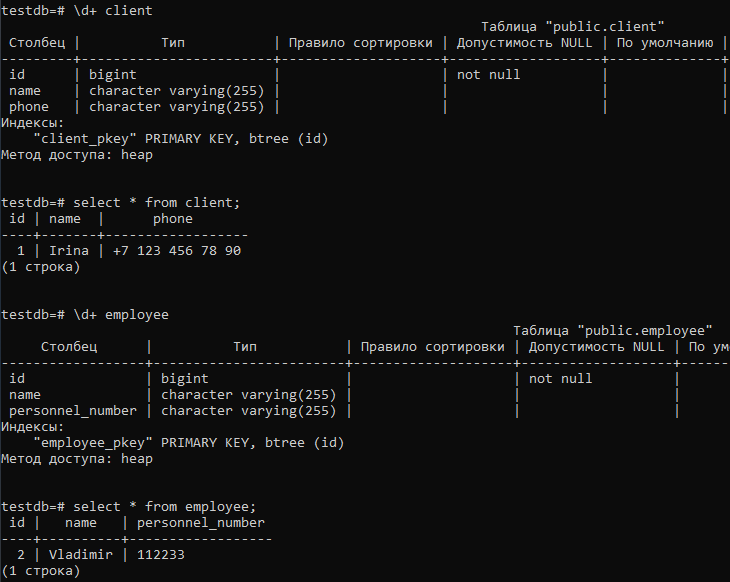
У них есть одинаковые поля ID и NAME, отображённые из класса Person, а также собственные поля PHONE и PERSONNEL_NUMBER.