Классы сущностей Java могут иметь иерархическую структуру и существует ряд стратегий отображения этой структуры в БД. Самой простой стратегией является отображение каждого конечного конкретного класса в отдельную таблицу с полным игнорированием полиморфных отношений.
То есть если классы Client и Employee наследуют класс Person, то Hibernate создаёт для каждого отдельную таблицу и при этом тот факт, что оба класса наследуют Person для Hibernate не будет иметь значения. Hibernate не будет способен искать объекты типа Person, составлять и возвращать из БД списки типа Person, в которых были бы смешаны данные из двух таблиц. Он будет работать с CLIENT и EMPLOYEE только как с абсолютно не связанными таблицами.
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Создадим абстрактный класс-предок для сущностей, отображаемых в БД и пометим его аннотацией @MappedSuperclass:
|
1 2 3 4 5 6 7 8 9 10 11 |
@MappedSuperclass public abstract class Person { @Id @GeneratedValue protected Long id; protected String name; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Создадим сами классы сущности (каждый в своём файле):
|
1 2 3 4 5 6 7 |
@Entity public class Client extends Person { private String phone; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
|
1 2 3 4 5 6 7 |
@Entity public class Employee extends Person { private String personnelNumber; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
У наследников нет поля id, они унаследуют его у Person, поэтому при создании таблиц у них это поле, во-первых, появится, во-вторых, будет одинакового типа с одинаковой стратегией генерации. Кроме того, оба наследника унаследуют поле name с одинаковыми настройками (в нашем случае настройки по умолчанию, т.е. VARCHAR(255)).
Создадим псевдо репозиторий для класса Person. Он не будет полноценным репозиторием Spring, но в нём можно будет определить общие методы, для которых Spring Data Jpa тем не менее сгенерирует имплементацию. Затем другие, настоящие, репозитории унаследуют этот псевдо репозиторий вместе со сгенерированными методами.
|
1 2 3 4 |
@NoRepositoryBean public interface PersonRepository<T extends Person> extends JpaRepository<T, Long> { List<T> findByName(String name); } |
Аннотация @NoRepositoryBean указывает Spring’у, что данный бин не будет полноценным репозиторием, но от него будут наследоваться другие репозитории. Поэтому Spring всё-таки создаст тело для метода findByName(), и он будет вызываться и работать через наследников.
Создадим собственно наследников, полноценные репозитории для доступа к таблицам CLIENT и EMPLOYEE (каждый в своём файле):
|
1 2 3 |
@Repository public interface ClientRepository extends PersonRepository<Client> { } |
|
1 2 3 |
@Repository public interface EmployeeRepository extends PersonRepository<Employee> { } |
Создадим тестовый класс, методы которого проверят работу репозитория:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
@SpringBootTest @TestMethodOrder(MethodOrderer.OrderAnnotation.class) class SpringHibernatePostgresqlApplicationTests { @Autowired ClientRepository clientRepository; @Autowired EmployeeRepository employeeRepository; @Test @Order(1) void clientTest() { Client client = new Client("Irina", "+7 123 456 78 90"); clientRepository.save(client); Client clientInDb = clientRepository.findById(client.getId()).get(); assertEquals(client, clientInDb); } @Test @Order(2) void employeeTest() { Employee employee = new Employee("Vladimir", "112233"); employeeRepository.save(employee); Employee employeeInDb = employeeRepository.findById(employee.getId()).get(); assertEquals(employee, employeeInDb); } @Test @Order(3) void personTest() { List<Employee> irinaEmployee = employeeRepository.findByName("Irina"); assertEquals(Collections.EMPTY_LIST, irinaEmployee); List<Client> irinaClient = clientRepository.findByName("Irina"); assertEquals(1, irinaClient.size()); } } |
Метод clientTest() создаёт объект соответствующего класса c некоторыми данными. С помощью репозитория сохраняет данные в базу, а затем убеждается, что если извлечь данные из базы по id, то они совпадают с сохранёнными. Если тест падает, убедитесь, что должным образом определены методы equals() и hashCode() и у класса Client, и у предка, класса Person.
Поверки, выполняемые тестовым методом employeeTest(), полностью аналогичны таковым у clientTest().
Метод personTest() показывает нам следующее. У обоих репозиториев есть родительский метод findByName(). Но поиск возможен только по каждой таблице отдельно. У нас нет возможности искать по всем Person’ам. В данной конфигурации тот факт, что Client и Employee являются наследниками Person для Hibernate не имеет никакого значения. Иерархия классов была учтена Hibernate’ом при создании таблиц, но при поиске она игнорируется.
Убедиться, что таблицы были созданы как и ожидалось, можно в консоли psql:
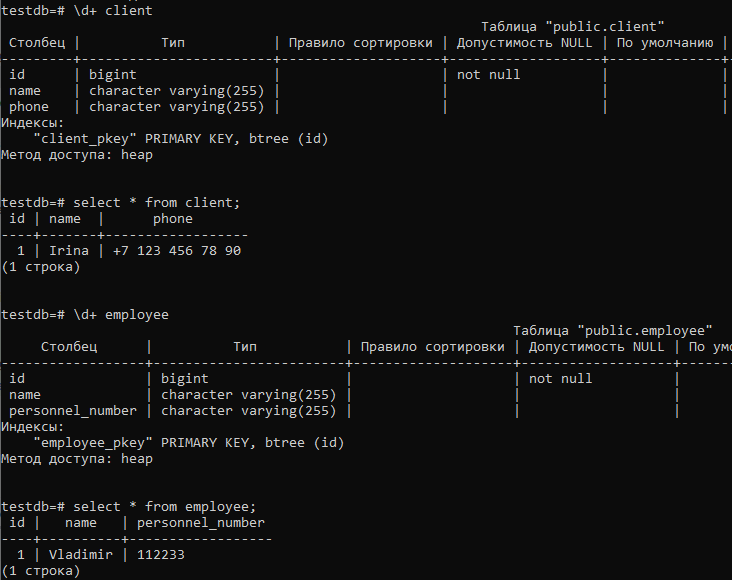
Созданы две таблицы CLIENT и EMPLOYEE, у каждой есть поля ID и NAME, как если бы мы определили их в классах Client и Employee, а не в предке. Очевидно, что в создании схемы данных иерархия наследования Java была учтена должным образом.
Такой способ отображения иерархически организованных классов предметной области имеет свои преимущества и недостатки. Главный недостаток — отсутствие полиморфизма. Действительно, есть ситуации, когда мы хотели бы составлять списки содержащие родственные сущности, имеющие общего предка. Но такая необходимость возникает не всегда.
Если мы, например, хотим вынести общие технические поля, такие как id, creation_date, modfication_date и т.п., в общего предка, то такой способ работы с наследованием нам более чем подходит. Действительно, технические поля (в частности id) есть практически у всех без исключения таблиц и вынести их в Java в отдельного предка — хорошая идея. Никакой полиморфизм в данном случае и не нужен. Таким образом мы получим то, что надо. Hibernate примет во внимание предков класса предметной области при создании таблицы и будет полностью игнорировать иерархию наследования при выборке данных.