Классы сущностей Java могут иметь иерархическую структуру и существует ряд стратегий отображения этой структуры в БД. Одной из стратегий является отображение всех наследников в одну таблицу по имени предка. Подробно сам способ, а также его преимущества и недостатки описаны здесь.
Особенностью единой таблицы для хранения данных всех потомков является наличие колонки-дискриминатора, по которой определяется, какая строка в какой именно класс потомок должна быть отображена.
Если по каким-то причинам нет возможности иметь такую колонку, то можно обойтись без неё. Тогда придётся указать Hibernate’у фрагмент SQL, который он будет добавлять в запрос для того, чтобы различать, на какой класс отображать данные той или иной строки таблицы.
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Также добавим в application.properties настройку, позволяющую видеть создаваемый Hibernate’ом SQL в консоли:
spring.jpa.show-sql=true
Создадим абстрактный класс-предок для сущностей, отображаемых в БД:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) @org.hibernate.annotations.DiscriminatorFormula( "case when PHONE is not null then 'CLIENT' else 'EMPLOYEE' end" ) public abstract class Person { @Id @GeneratedValue protected Long id; protected String name; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Мы помечаем класс-предок аннотацией @Entity и заводим в нём поле id с аннотацией @Id. Классам- потомкам это поле не понадобится. Аннотация @Inheritance с параметром strategy = InheritanceType.SINGLE_TABLE указывает Hibernate’у сохранять все данные всех потомков этого класса в единую таблицу. Таблица получается ненормализованной, все поля потомков будут отображены в nullable колонки.
Аннотация @org.hibernate.annotations.DiscriminatorFormula предписывает Hibernate’у вместо создания специальной колонки-дискриминатора, по значению которой можно определить к какому из классов-потомков относится содержимое конкретной строки, использовать переданный в параметре value фрагмент SQL, для этих целей. В каждый запрос на выборку Hibernate будет добавлять этот фрагмент, чтобы определить, к какому классу-потомку относятся данные каждой строки, попавшей в выборку.
Создадим классы потомки, каждый в своём файле:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
@Entity @DiscriminatorValue("CLIENT") public class Client extends Person { private String phone; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } @Entity @DiscriminatorValue("EMPLOYEE") public class Employee extends Person { private String personnelNumber; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Классы-потомки также помечаются аннотацией @Entity. Кроме того они снабжаются аннотацией @DiscriminatorValue, на значение которой мы смотрим в нашем фрагменте SQL кода, который должен различать потомков в зависимости от содержимого строки.
В нашем примере фрагмент был таким:
case when PHONE is not null then 'CLIENT' else 'EMPLOYEE' end
Предполагается, что если в той или иной строке значение поля PHONE не нулл, то эта строка должна отобразиться в класс CLIENT. Такой подход сразу выделяется двумя серьёзными недостатками:
- Поскольку поле phone специфично для класса-потомка Client, то в таблице соответствующая колонка PHONE не может иметь ограничение NOT NULL. Соответственно мы обязаны тем или иным образом в коде гарантировать, что у объектов класса Client перед сохранением данных это поле будет обязательно заполнено. Иначе при выборке мы получим трудноуловимые ошибки.
- Сам по себе фрагмент SQL, используемый в качестве дискриминатора, должен быть написан на диалекте конкретной БД и не может быть никак обобщён. Конкретно та строка точно работает в PostreSQL, во многих других СУБД. Но гарантии, что она будет работать должным образом во всех СУБД, поддерживаемых Hibernate’ом — нет.
Создадим репозитории для класса-предка и классов-потомков (каждый в своём файле):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
@Repository public interface PersonRepository<T extends Person> extends JpaRepository<T, Long> { List<T> findByName(String name); } @Repository public interface ClientRepository extends PersonRepository<Client> { } @Repository public interface EmployeeRepository extends PersonRepository<Employee> { } |
Наследование ClientRepository и EmployeeRepository от PersonRepository необязательно, но в данном случае оно имеет смысл.
Создадим тест, который продемонстрирует вышеизложенное:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
@SpringBootTest @TestMethodOrder(MethodOrderer.OrderAnnotation.class) class SpringHibernatePostgresqlApplicationTests { @Autowired ClientRepository clientRepository; @Autowired EmployeeRepository employeeRepository; @Autowired PersonRepository<?> personRepository; @Test @Order(1) void clientTest() { Client client = new Client("Irina", "+7 123 456 78 90"); clientRepository.save(client); Client clientInDb = clientRepository.findById(client.getId()).get(); assertEquals(client, clientInDb); } @Test @Order(2) void employeeTest() { Employee employee = new Employee("Vladimir", "112233"); employeeRepository.save(employee); Employee employeeInDb = employeeRepository.findById(employee.getId()).get(); assertEquals(employee, employeeInDb); } @Test @Order(3) void personTest() { List<? extends Person> persons = personRepository.findByName("Irina"); assertFalse(persons.isEmpty()); assertTrue(persons.get(0) instanceof Client); } } |
Метод clientTest() создаёт объект соответствующего класса с некоторыми данными. С помощью репозитория сохраняет данные в базу, а затем убеждается, что если извлечь данные из базы по id, то они совпадают с сохранёнными. Если тест падает, убедитесь, что должным образом определены методы equals() и hashCode() и у класса Client, и у предка, класса Person.
В консоли мы можем посмотреть, как Hibernate делает выборку только строк, отображаемых в объекты Client, с использованием заданного нами фрагмента SQL:
select c1_0.id,c1_0.name,c1_0.phone from person c1_0 where case when c1_0.PHONE is not null then 'CLIENT' else 'EMPLOYEE' end='CLIENT' and c1_0.id=?
Поверки, выполняемые тестовым методом employeeTest(), полностью аналогичны таковым у clientTest().
Метод personTest() помимо прочего демонстрирует выборку по всей таблице. Также с использованием нашего SQL фрагмента:
select p1_0.id,case when p1_0.PHONE is not null then 'CLIENT' else 'EMPLOYEE' end,p1_0.name,p1_0.phone,p1_0.personnel_number from person p1_0 where p1_0.name=?
Посмотрим на созданную схему БД:
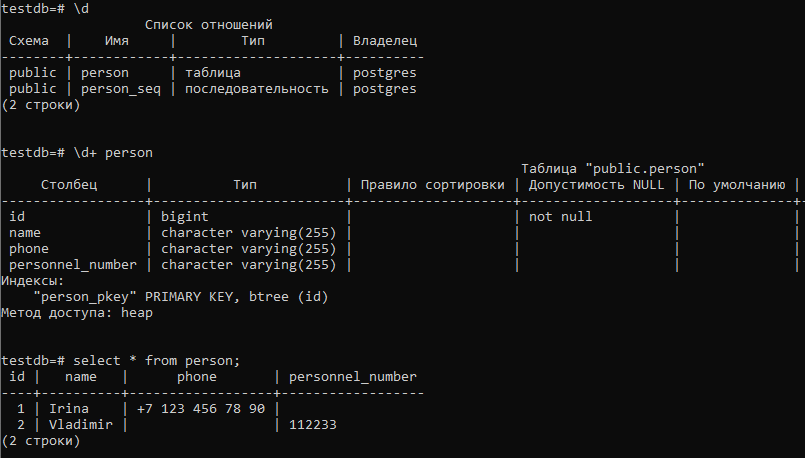
Как видим, создана одна таблица для хранения данных всех классов-потомков, но без колонки-дискриминатора. Решение о том, к какому классу-потомку относятся данные конкретной строки принимается на основе работы заданного в аннотации @DiscriminatorFormula фрагмента SQL, добавляемого во все запросы на выборку из этой таблицы.
Наверное сложно представить ситуацию, когда мы, создавая схему БД, не можем себе позволить создать колонку-дискриминатор. Однако довольно вероятна ситуация, когда схема уже есть, но мы не можем вносить в неё изменения. В этом случае использование @DiscriminatorFormula может оказаться подходящим решением.