Мы привыкли использовать задействованные по умолчанию в Hibernate преобразования Java типов в соответствующие типы нашей СУБД. Так для полей типа java.lang.String создаётся колонка типа VARCHAR, для java.lang.Long — BIGINT (или аналоги специфичные для конкретного вендора).
При этом в Hibernate есть возможность создавать собственные конвертеры, с помощью которых можно преобразовывать данные собственных типов в стандартные Java типы (например, в String), чтобы Hibernate мог их сохранить, а затем и восстановить из колонок соответствующих типов. Например, наш кастомный тип FullName может быть конвертирован в String и сохранён в поле типа VARCHAR.
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
|
1 |
spring.jpa.hibernate.ddl-auto=update |
Создадим класс, данные полей которого мы будем конвертировать в строку и хранить в простой VARCHAR колонке БД:
|
1 2 3 4 5 6 |
public class FullName { private String firstName; private String lastName; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Как видите сам класс ничем не аннотирован и вообще «не знает», что данные его полей будут во что-то конвертированы. Это самый обычный java bean.
Создадим конвертер для класса FullName, который будет способен конвертировать объекты этого класса в строку, а также уметь парсить строку, чтобы воссоздавать из неё объекты типа FullName. Для этого конвертер должен имплементировать интерфейс jakarta.persistence.AttributeConverter:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@Converter public class FullNameToStringConverter implements AttributeConverter<FullName, String> { @Override public String convertToDatabaseColumn(FullName fullName) { return fullName.getFirstName() + " " + fullName.getLastName(); } @Override public FullName convertToEntityAttribute(String dbData) { String[] nameParts = dbData.split(" "); return new FullName(nameParts[0], nameParts[1]); } } |
Создадим класс предметной области следующего содержания:
|
1 2 3 4 5 6 7 8 9 10 11 |
@Entity public class Person { @Id @GeneratedValue private Long id; @Convert(converter = FullNameToStringConverter.class) private FullName fullName; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Данный класс является сущностью и Hibernate создаст для него таблицу. Причём данные поля fullName будут храниться в специальной колонке типа VARCHAR, так как мы указали с помощью аннотации @Convert конвертер, который типизирован типами FullName и String, что заставит Hibernate создать для хранения данных объектов этого класса в БД колонку типа VARCHAR, как если бы тип поля был String, а не FullName.
Кроме того, мы могли бы указать над этим полем аннотацию @Column и в её параметрах задать все необходимые свойства и ограничения колонки: её размер, возможность хранить нуллы и т.п.
Создадим тестовый метод, который докажет, что при сохранении данных объекта в БД и последующем извлечении данных в новый объект, содержимое объектов будет идентичным:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
@SpringBootTest class SpringHibernatePostgresqlApplicationTests { @Autowired PersonRepository personRepository; @Test void checkConverter() throws Exception { FullName fullName = new FullName("Irina", "Pantyukhina"); Person irina = new Person(null, fullName); personRepository.save(irina); Person irinaInDb = personRepository.findById(irina.getId()).get(); assertEquals(irina, irinaInDb); } } |
Если тест провалится, то убедитесь, что вы должным образом переопределили методы equals() и hashCode().
Давайте посмотрим, какую схему создал Hibernate в БД и как в ней сохранились данные:
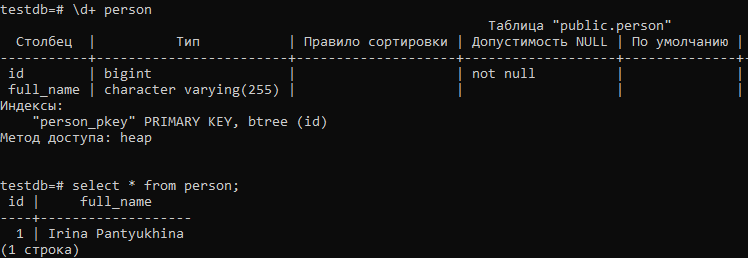
Как видите, для поля fullName была создана колонка FULL_NAME типа VARCHAR и объект поля fullName был конвертирован в строку нашим конвертером, как мы её видим в базе. Затем при выборке строка была конвертирована обратно в объект, что доказано нашим тестом.