При автоматической генерации схемы БД на основе классов предметной области спецификация JPA и Hibenate, как её реализация, позволяют очень гибко настраивать имена таблиц, соответствующих сущностям.
Добавьте в файл application.properties тестового проекта следующие строки, чтобы можно было видеть вывод Hibernate’а:
|
1 2 |
spring.jpa.properties.hibernate.show_sql=true spring.jpa.properties.hibernate.format_sql=true |
Значение по умолчанию
Если никак не управлять именами таблиц, создаваемых в пару к классам предметной области, то имена будут создаваться автоматически, на основании имён классов. При этом кемелкейс имён классов будет преобразован в нижнее подчёркивания имён таблиц.
Например, для такой сущности:
|
1 2 3 4 5 6 |
@Entity public class FullName { @Id @GeneratedValue Long id; } |
будет создана таблица с именем FULL_NAME. Если чувствительность к регистру специально не настраивалась, то СУБД скорее всего к регистру символов в именах не чувствительна. При этом в PostgreSQL имена будут по умолчанию создаваться в нижнем регистре. Но, тем не менее, говоря об именах таблиц и колонок БД, как правило, их пишут в верхнем регистре. Поэтому, запустив этот код в нашем приложении мы увидим в PostgreSQL, мы увидим full_name.
Произвольное именование таблицы
Если мы попробуем запустить проект с таким классом:
|
1 2 3 4 5 6 |
@Entity public class User { @Id @GeneratedValue Long id; } |
То во время запуска, в консоли увидим такое сообщение:
|
1 2 3 4 5 |
GenerationTarget encountered exception accepting command : Error executing DDL " create table user ( id bigint not null, primary key (id) )" via JDBC Statement |
Так как USER является ключевым словом в СУБД PostgreSQL, то нельзя просто так создать таблицу с таким именем.
Чтобы переопределить имя таблицы, соответствующее классу сущности, над классом сущности можно поместить аннотацию @Table с параметром name:
|
1 2 3 4 5 6 7 |
@Entity @Table(name = "USERS") public class User { @Id @GeneratedValue Long id; } |
После запуска приложения в консоли мы должны увидеть такое сообщение:
|
1 2 3 4 5 6 7 |
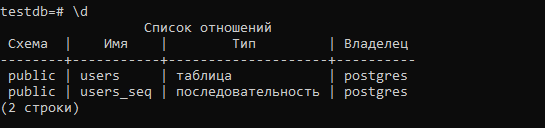
Hibernate: create table users ( id bigint not null, primary key (id) ) Hibernate: create sequence users_seq start with 1 increment by 50 |
И Hibernate создаст следующую таблицу:
Помимо name, в @Table также можно передать параметры catalog и schema:
|
1 2 3 4 5 6 7 |
@Entity @Table(schema = "public", name = "USERS") public class User { @Id @GeneratedValue Long id; } |
↓
|
1 2 3 4 5 6 7 |
Hibernate: create table public.users ( id bigint not null, primary key (id) ) Hibernate: create sequence users_seq start with 1 increment by 50 |
Создание таблиц, имена которых совпадают с ключевыми словами СУБД
Если необходимо создать таблицу, имя которой будет совпадать с одним из ключевых слов в СУБД, то имя такой таблицы нужно заключить в кавычки. Причём, поскольку это делается в параметре аннотации, который и так в кавычках, то придётся использовать экранирование:
|
1 2 3 4 5 6 7 |
@Entity @Table(name = "\"USER\"") public class User { @Id @GeneratedValue Long id; } |
Поскольку, работая с Spring Boot 3 с технологией Spring Data JPA, мы можем быть уверены, что имеплементацией JPA всегда будет Hibernate, то можно использовать и более наглядный синтаксис с обратными кавычками:
|
1 |
@Table(name = "`USER`") |
Но нужно иметь в виду, что такой вариант работает только с Hibernate и может не работать, с другой имплементацией JPA.
Запустив приложение, мы увидим в логах запуска следующий вывод:
|
1 2 3 4 |
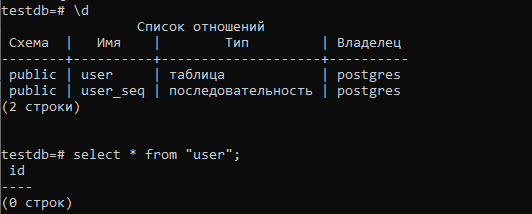
create table "user" ( id bigint not null, primary key (id) ) |
Теперь при создании запроса к такой таблице нужно знать, как в конкретной СУБД оборачивать имя такой таблицы. Например, в PostgreSQL такое имя заключается в двойные кавычки:
В других СУБД будет по-другому. Например, в MS SQL SERVER это будет [USER], а в MySQL — ‘USER’.