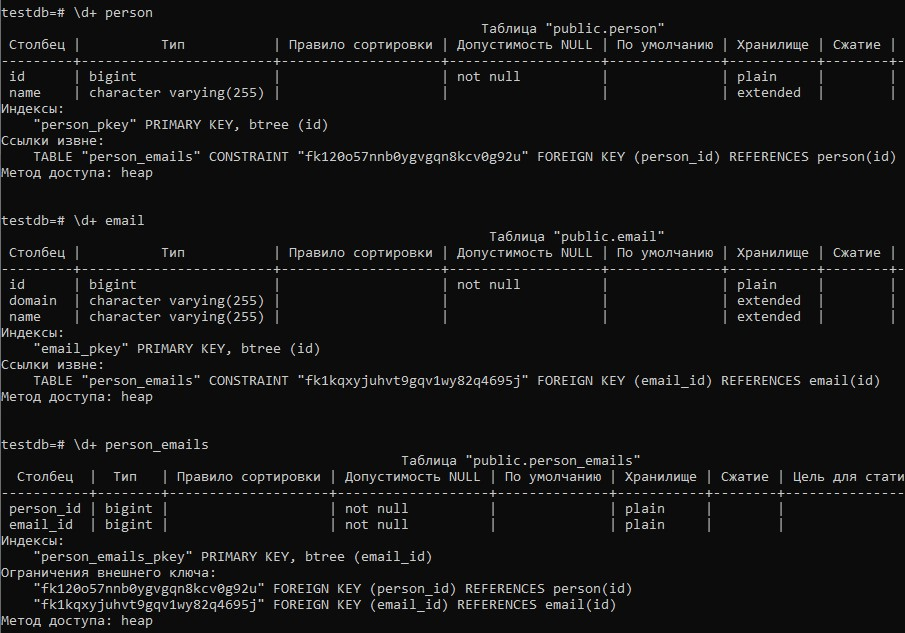
В JPA/Hibernate есть несколько способов описания двунаправленной связи между сущностями. Одним из которых является связь через третью таблицу. Если сущности слабо связаны друг с другом и связи между ними не постоянны, то такой подход подход позволяет избежать null значений в таблицах.
Например, если у нас есть две сущности: Person и Email, которые достаточно независимы друг от друга в том смысле, что не за каждым человеком закреплён адрес почты, а также не про каждый адрес известно чей он, то при создании связи через простой внешний ключ некоторые поля будут содержать null. Если такая ситуация недопустима, то организация связи через третью таблицу, эту проблему решает. Цена решения — затраты на join’ы при выборке.
Подготовка
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Код
Классы предметной области
Создадим класс предметной области Person:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
@Entity public class Person { @Id @GeneratedValue private Long id; private String name; @OneToMany(mappedBy = "person", fetch = FetchType.EAGER) private List<Email> emails = new ArrayList<>(); //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Мы помечаем поле со списком объектов Email аннотацией @OneToMany, тем самым устанавливая первую сторону двусторонней связи между сущностями. В параметре mappedBy мы указываем имя поля, которое в свою очередь будет ссылаться на объект класса Person.
Мы устанавливаем параметр fetch равным FetchType.EAGER, после чего связанные объекты Email будут автоматически запрашиваться при выборке строк из таблицы PERSON. Такой подход в отличие от «ленивой» выборки связанных сущностей не требует выполнения запроса внутри транзакции, которые мы в данным случае не рассматриваем.
Создадим класс предметной области Email, в котором организуем связь типа один-ко-многим между Person и Email:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
@Entity public class Email { @Id @GeneratedValue private Long id; @ManyToOne @JoinTable( name = "PERSON_EMAILS", joinColumns = @JoinColumn(name = "EMAIL_ID"), inverseJoinColumns = @JoinColumn(nullable = false) ) private Person person; private String name; private String domain; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Мы помечаем поле Person person аннотацией @ManyToOne, замыкая таким образом двустороннюю связь между сущностями Person и Email.
В помощью аннотации @JoinTable мы описываем способ создания связи — а именно через таблицу. В параметре name мы указываем имя соединяющей таблицы.
Параметр joinColumns описывает колонку (в данном случае одну) создаваемой таблицы, которая будет ссылаться на таблицу соответствующую текущему классу EMAIL. Здесь мы указали имя такой колонки (впрочем, оно совпадает с именем, которое Hibernate создал бы автоматически).
Параметр inverseJoinColumns описывает колонку (опять только одну), которая будет ссылаться на таблицу PERSON. В данном случае в описании колонки мы ограничились только тем, что повесили на неё ограничение NOT NULL с помощью параметра nullable = false. Другие параметры оставили по умолчанию (например, имя колонки автоматически будет PERSON_ID).
Таким образом в параметрах joinColumns и inverseJoinColumns мы можем описать колонки соединяющей таблицы, которые ссылаются на соединяемые. Можем задать им произвольные имена и повесить необходимые ограничения.
Репозитории
Создадим репозиторий для класса Person:
|
1 2 3 |
@Repository public interface PersonRepository extends JpaRepository<Person, Long> { } |
Также создадим репозиторий для класса Email:
|
1 2 3 |
@Repository public interface EmailRepository extends JpaRepository<Email, Long> { } |
Проверка кода
Напишем тест, который продемонстрирует работу кода:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
@SpringBootTest class SpringHibernatePostgresqlApplicationTests { @Autowired PersonRepository personRepository; @Autowired EmailRepository emailRepository; @Test void oneToManyViaTableTest() { Person irina = new Person("Irina"); personRepository.save(irina); List<Email> emails = List.of( new Email(irina, "irina", "russia.ru"), new Email(irina, "irina", "mail.ru") ); emailRepository.saveAll(emails); irina.setEmails(emails); Person irinaInDb = personRepository.findById(irina.getId()).get(); assertEquals(emails, irinaInDb.getEmails()); } } |
Мы создаём объект Person irina и сохраняем его данные в БД.
Заем мы создаём два объекта типа Email, каждому из которых в конструктор передаём ранее созданный объект irina. Таким образом мы инициализируем поле Person person этих объектом и соответственно создаём связь между сущностями. Затем мы сохраняем созданные объекты в БД.
Следующим шагом мы извлекаем поиском по id данные объекта irina и присваиваем объект с данными переменной irinaInDb. В ассерте мы вызываем метод irinaInDb.getEmails() и сравниваем результат выполнения метода с ранее созданными объектами.
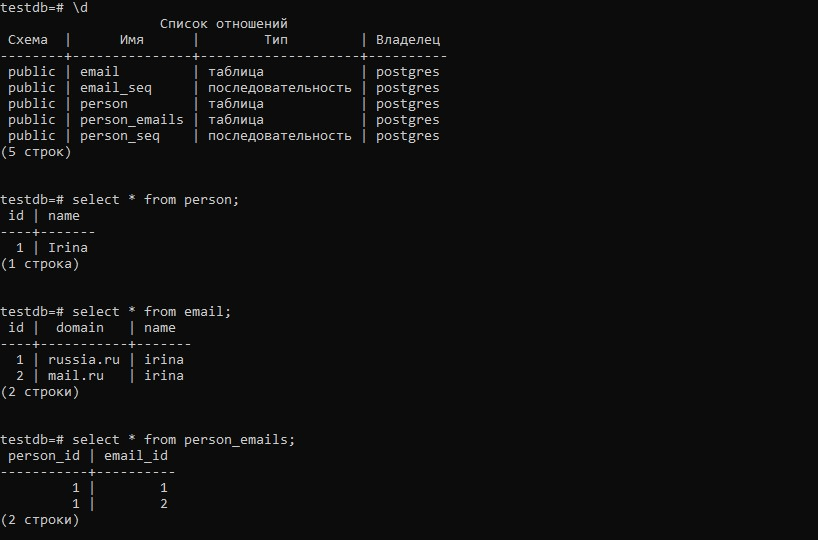
Хотя мы никогда не устанавливали объекту irina список адресов электронной почты, достаточно было, что мы связали адреса с объектом irina. В итоге Hibernate всё равно создал связь в БД через третью таблицу и мы можем как извлекать список адресов, имея в руках объект Person, так и получать объект Person, имея в руках объект Email.
Рассмотрим состояние таблиц БД после выполнения выполнения кода:
Рассмотрим схему таблиц, созданных Hibernate’ом: