Классы предметной области в Java могут содержать поля перечисляемых типов (enum’ы) и данные этих полей, разумеется должны сохранятся в БД и восстанавливаться из БД. В силу естественных ограничений в БД может быть сохранено либо числовое значение enum’а, соответствующее его порядку, либо его строковое значение. Отвечает за это аннотация @Enumerated.
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Создадим два перечисления (лучше каждый в своём файле):
|
1 2 3 4 |
public enum Status { GRATA, NON_GRATA } |
|
1 2 3 4 |
public enum Country { RUSSIA, CHINA } |
Создадим класс предметной области следующего содержания:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@Entity public class Person { @Id @GeneratedValue private Long id; private String name; @Enumerated(EnumType.STRING) private Status status; @Enumerated(EnumType.ORDINAL) private Country country; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Поле status мы пометили аннотацией @Enumerated с параметром value = EnumType.STRING. Это означает, что при сохранении данных в БД будет сохранятся строковое значение enum’а. То есть, если status будет равен Status.GRATA, то в БД будет сохранена строка «GRATA».
Поле country помечено аннотацией @Enumerated с value = EnumType.ORDINAL. Это значит, что в БД будет сохранятся порядковый номер перечисления, начия с нуля. То есть в нашем случае для RUSSIA будет сохраняться 0, а для CHINA — 1.
Оба вариант сохранения имеют свои преимущества и чреваты своими проблемами. Всё зависит от того, какой вид рефакторинга с большей вероятностью будет применён к перечислению по мере развития и доработки проекта. Если больше вероятность того, что перечисления будут переименовываться, а новые просто дописываться в конец, то лучше сохранять порядковый номер. Если мы уверены, что значений перечисления будет много, они не будут переименовываться, но могут быть упорядочены внутри перечисления, например, по алфавиту или как-то сгруппированы. То, конечно, лучше сохранять их по имени, а не по порядковым номерам.
В любом случае рефакторинг перечислений, используемых в классах предметной области, это всегда определённые риски рассинхронизации с данными в БД.
Создадим репозиторий:
|
1 2 3 |
@Repository public interface PersonRepository extends JpaRepository<Person, Long> { } |
Создадим тест:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
@SpringBootTest class SpringHibernatePostgresqlApplicationTests { @Autowired PersonRepository personRepository; @Test void checkEnumsORM() { Person irina = new Person("Irina", Status.GRATA, Country.RUSSIA); Person saved = personRepository.save(irina); Person irinaInDb = personRepository.findById(saved.getId()).get(); assertEquals(Status.GRATA, irinaInDb.getStatus()); assertEquals(Country.RUSSIA, irinaInDb.getCountry()); } } |
Тест сохранит в БД строку, а затем её же и извлечёт, что докажет, что перечисления благополучно отобразились в соответствующие типы данных в БД, а затем обратно в перечисления.
Посмотрим, как это выглядит собственно в БД:
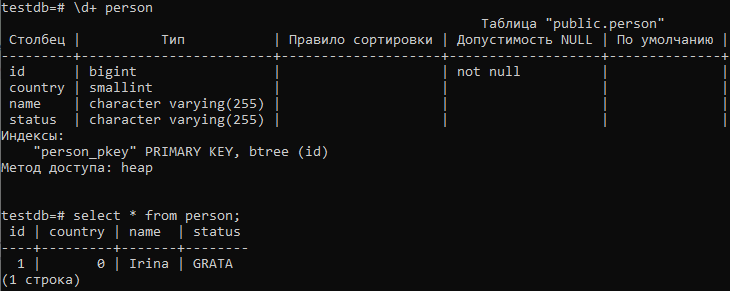
Для поля country была создана колонка типа smallint, а для status — varchar(255). Соответственно в таблице в колонку country сохранилось числовое значение перечисления, а в status — строковое. Всё как мы и обозначили в наших аннотациях над полями класса предметной области Person.