Hibernate позволяет настроить на уровне БД каскадное удаление данных дочерних таблиц, при удалении строки родительской таблицы. Поскольку не все СУБД поддерживают данных функционал, то его использование может отразиться на переносимости приложения между разными СУБД.
Подготовка
Создадим базовое веб-приложения на связке Spring Boot 3 + Hibernate + PostgreSQL
Убедитесь, что файле /src/main/resources/application.properties есть следующая строка, позволяющая Hibernate’у автоматически создавать (и обновлять) схему БД при запуске приложения на основании аннотаций в классах предметной области:
spring.jpa.hibernate.ddl-auto=update
Код
Создадим двунаправленную связь между двумя классами-сущностями. Для этого сперва создадим класс предметной области следующего содержания:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
@Entity public class Address { @Id @GeneratedValue private Long id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "PERSON_ID", nullable = false) private Person person; @Column(nullable = false) private String city; @Column(nullable = false) private String street; @Column(nullable = false) private String house; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
А затем следующий класс-сущность:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
@Entity public class Person { @Id @GeneratedValue private Long id; private String name; private Integer age; @OneToMany(mappedBy = "person") @org.hibernate.annotations.OnDelete( action = org.hibernate.annotations.OnDeleteAction.CASCADE ) private List<Address> addresses; //Конструкторы, геттеры и сеттеры, equals(), hashCode() и т.д. } |
Подробное описание аннотаций и их параметров, используемых при создании двунаправленной связи, см. в соответствующей статье.
С помощью аннотации @org.hibernate.annotations.OnDelete и параметра action = org.hibernate.annotations.OnDeleteAction.CASCADE мы указываем Hibernate’у наложить ограничение ON DELETE CASCADE на внешний ключ PERSON_ID таблицы ADDRESS.
Обратим внимание на следующие моменты. Во-первых, аннотацию мы размещаем над полем addresses класса Person, хотя ограничение будет наложено на таблицу ADDRESS. Это необычно, но в этом есть своя логика.
Во-вторых, этот функционал доступен только в Hibernate. Его нет в JPA, поэтому другие провайдеры персистенции его не поддерживают. Хотя, если речь не о легаси, то это скорее всего не проблема.
В-третьих, необходимо, чтобы сама СУБД поддерживала ограничения вида ON DELETE CASCADE.
Создадим репозиторий для класса Address:
|
1 2 3 4 |
@Repository public interface AddressRepository extends JpaRepository<Address, Long> { List<Address> findByPerson(Person person); } |
Далее создадим репозиторий для класса Person:
|
1 2 3 |
@Repository public interface PersonRepository extends JpaRepository<Person, Long> { } |
Напишем тестовый метод, который продемонстрирует работу настроек:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
@SpringBootTest @Transactional class SpringHibernatePostgresqlApplicationTests { @Autowired PersonRepository personRepository; @Autowired AddressRepository addressRepository; @Test void onDeleteCascadeTest() throws Exception { Person irina = new Person("irina", 28); List<Address> irinasAddresses = List.of( new Address(irina, "Москва", "Садовая", "12"), new Address(irina, "Воскресенск", "СНТ Строитель", "424") ); irina.setAddresses(irinasAddresses); personRepository.save(irina); addressRepository.saveAll(irinasAddresses); List<Address> addressesInDb = addressRepository.findByPerson(irina); assertTrue(addressesInDb.containsAll(irinasAddresses)); personRepository.delete(irina); addressesInDb = addressRepository.findByPerson(irina); //Благодаря настройке OnDeleteAction.CASCADE с удалением строки данных объекта irina из таблицы PERSON //были удалены и ссылающиеся на неё строки таблицы ADDRESS assertTrue(addressesInDb.isEmpty()); } } |
В данном методе мы создаём объект irina Типа Person и список из двух объектов Address. Мы устанавливаем ссылки объектов друг на друга. У каждого объекта Address поле person заполняется ссылкой на объект irina в конструкторе. Затем список Address устанавливается в поле addresses объекта irina через сеттер: irina.setAddresses(irinasAddresses).
Мы сохраняем в БД как сам объект irina, так и список адресов. Поскольку и Person, и Address объявлены сущностями (@Entity), то мы обязаны сохранять их с помощью их собственных репозиториев, несмотря на наличие связи между ними. Что мы и делаем.
Затем мы извлекаем адреса объекта irina из БД. Утверждение assertTrue(addressesInDb.containsAll(irinasAddresses)) доказывает, что адреса были сохранены и теперь доступны для выбрки.
Затем мы удаляем данные объекта irina из БД и снова пытаемся извлечь данные об адресах. Однако теперь список адресов пуст. Утверждение assertTrue(addressesInDb.isEmpty()) доказывает это. Значит строки таблицы ADDRESS, чей внешний ключ ссылался на id удалённого объекта irina, были удалены автоматически.
Рассмотрим описание таблицы ADDRESS, созданной Hibernate’ом:
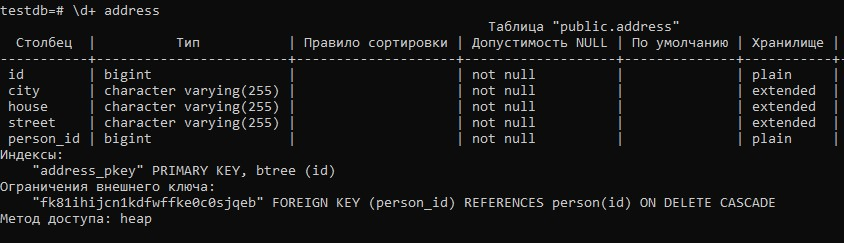
У данного подхода есть преимущество перед другими способами автоматического удаления дочерних строк. Каскадное удаление быстрое. В других случаях автоматического удаления Hibernate удаляет строки по одной.
Однако этот подход сохраняет все прочие недостатки автоматического удаления как такового. Во-первых, мы увязываем жизненный цикл одних сущностей с жизненным циклом других. Хотя жизненные циклы сущностей обычно взаимонезависимые (адрес не перестаёт существовать, если кто-то переезжает).
При автоматическом удалении адресов в БД, в коде по прежнему могут остаться ссылки на соответствующие объекты. Это приведёт к несогласованности состояния в БД и в коде.